Thinking About Data Systems
Data system is a combination of small, individual components, each with its own responsibility.
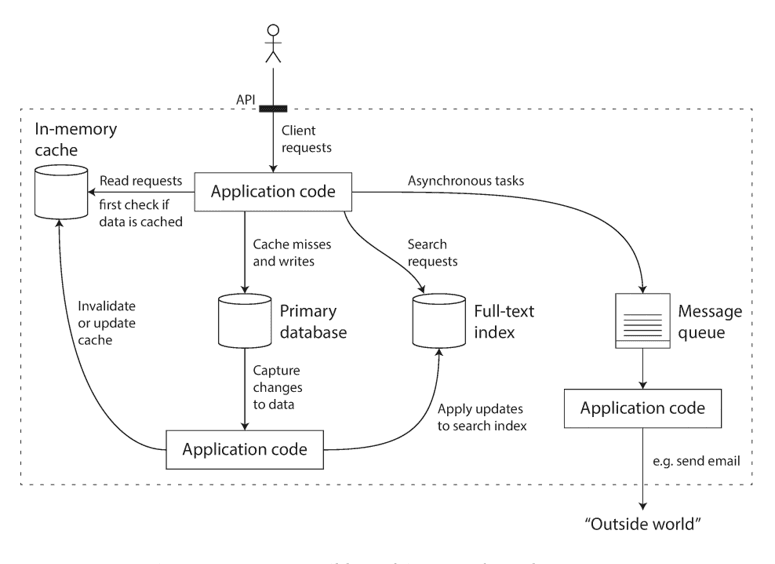
There are three concerns that are important in most software systems.
Reliability: The system should continue to work correctly even in the face of adversityScalability: As the system grows(in data volume, traffic, or complexity), there should be reasonable ways of dealing with that growth.Maintainability: Overtime, many different people will work on the system, and they should be able to work on it productively
Reliability
The things that can go wrong are called faults, and systems that anticipate faults and can cope with them are called fault tolerant/resilient.
Note that a fault is not the same as a failure.
Fault: usually defined as one component of the system deviating from its specFailure: the system as a whole scopes providing the required service to the user
In fault-tolerant systems, it can make sense to increase the rate of faults by triggering them deliberately.
Example of this approach is Netflix's Chaos Monkey. (The Netflix Simian Army) (opens in a new tab).
Hardware Faults
Examples: Hard disks crash, RAM becomes faulty, the power grid has a blackout, someone unplugs the wrong network cable.
Hardware disks are reported as having a mean time to failure (MTTF) of about 10 - 50 years. Thus, on a storage cluster with 10,000 disks, we should expect on average one disk to die per day.
One naive solution is to add redundancy to the individual hardware components. When one component dies, the redundant component can take its place while the broken component is replaced.
Software Errors
Software error ar harder to anticipate than hardware faults.
- A software bug
- A runaway process that uses up some shared resource
- A software that the system depends on that slow down, becomes unresponsive, or returns unexpected responses.
- Cascading failures, where a small fault in one component triggers a fault in another component, which in turn triggers further faults.
Human Errors
We design systems, and therefore we can also create errors such as misconfiguring systems or writing code with wrong logic. To prevent human errors, we can
- Design systems in a way that minimizes opportunities for error
- Add decoupling. ex. Setting up development and production environment
- TDD
How Important Is Reliability?
Very important, as bugs in business applications cause lost productivity.
Scalability
Scalability is the term we use to describe a system's ability to cope with increased load. There are several steps required to achieve scalability.
- We must define what is the
loadfor the system. - We must define how
performantthe system should be.
Describing Load
We need to succinctly describe the current load on the system; only then we can discuss growth questions (ex. what happens if our load doubles?)
Load can be described with a few numbers which we call load parameters.
Load parameters depend on the architecture of your system
- requests/second to a web server,
- the ratio of read/writes in a database
- number of simultaneously active users in a chat room
- the hit rate on a cache
Twitter System Design Example
In twitter (as of November 2012), two main operations were:
Post Tweet: A user can publish a new message to their followersHome Timeline: A user can view tweets posted by the people they follow
Twitter's scaling challenge was not primarily due to tweet volume, but due to fan-out: each user follows many people, and each user is followed by many people.
There are two possible solutions.
1. Without Caching
- When a user posts tweet, inserts the new tweet into a global collection of tweets.
- When a user requests their home timeline,
- look up all the people they follow
- find all tweets for each of those users
- then merge all tweets
2. Maintain a cache for each user's home timeline (think of mailbox).
- When a user posts a tweet,
- look up all the people who follow that user
- insert the new tweet into each of their home timeline caches
- When a user request their home timeline, simply return the cached timeline (request cost is very cheap).
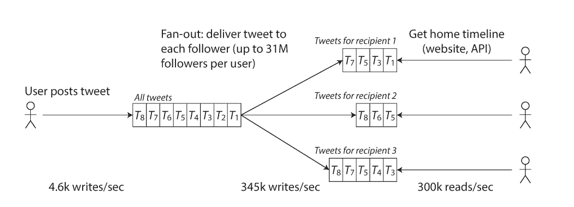
Downside of approach 1 was that the systems struggled to keep up with the load of home timeline queries. Therefore, twitter switched to approach 2. This works better because the average rate of published tweets is almost two orders of magnitute lower than the rate of home time line reads, so in this case it's preferable to do more work at write and less at read.
Downside of approach 2, however, is that posting a tweet now requires a lot of extra work. Imagine a user with 35m follwers. Then, posting(write) must be done 35m times.
Current solution of twitter is the hybrid of two approaches: most follow approach 2, but users with a very large number of followers are excepted from fan-out. Tweets from any celebrities are fetched seperately and merged with follower's timeline when it is read, like in approach 1.
Describing Performance
Once you have described the load on your system, you can investigate what happens when the load increases.
- When you increase a load parameter and keep the system resources (CPU, memory, network bandwidth, etc.) unchanged, how is the performance of your system affected?
- When you increase a load parameter, how much do you need to increase the resources if you want to keep performance unchanged?
Examples of performance metrics:
throughput: the number of records we can process per secondresponse time: time between a client sending a request and receiving a responselatency: duration that a request is waiting to be handled (await).
Mean is often not a very good metric for describing performance. Usually it is better to use percentiles.
In order to figure out how bad your outliers are, you can look at higher percentiles: the 95th, 99th, and 99.9th percentiles are common (abbreviated p95, p99, and p999).
High percentiles of response times, also known as tail latencies, are important because they directly affect users’ experience of the service.
For example, Amazon describes response time requirements for internal services in terms of the 99.9th percentile, even though it only affects 1 in 1,000 requests. This is because the customers with the slowest requests are often those who have the most data on their accounts because they have made many purchases—that is, they’re the most valuable customers
Percentiles are often used in service level objects(SLOs) and service level agreements(SLA).
An SLA may state that the service is considered to be up if it has a median response time of less than 200 ms and a 99th percentile under 1 s (if the response time is longer, it might as well be down), and the service may be required to be up at least 99.9% of the time.
Queuing delays often account for a large part of the response time at higher percentiles.
head-of-line blocking: as server has capacity limit, it only takes a a small number of slow requests to hold the processing of subsequent requests.
When generating load artificially in order to test the scalability of a system, the load-generating client needs to keep sending requests independently of the response time.
Approaches for Coping with Load
Scaling Up: Moving to more powerful machineScaling Out: Distribute load across multiple smaller machines.
These terms are often a talk of dichotomy, but in reality both approaches should be combined.
Maintainability
We can and should design software in such a way that it will hopefully minimize pain during maintenance, and thus avoid creating legacy software ourselves.
Operability: Make it easy for operations teams to keep the system running smoothly.Simplicity: Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system.Evolvability: Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change.
Operability: Making Life Easy for Operations
Good operability means making routine tasks easy, allowing the operations team to focus their efforts on high-value activities. A good operations team typically is responsible for the following, and more.
- Monitoring the health of the system and quickly restoring service if it goes into a bad state
- Keeping tabs on how different systems affect each other, so that a problematic change can be avoided before it causes damage
- Establishing good practices and tools for deployment, configuration management, and more
Simplicity: Managing Complexity
Making a system simpler does not necessarily mean reducing its functionality; it can also mean removing accidental complexity.
One of the best tools we have for removing accidental complexity is abstraction.
Evolvability: Making Change Easy
In terms of organizational processes, Agile working patterns provide a framework for adapting to change. The Agile community has also developed technical tools and patterns that are helpful when developing software in a frequently changing environment, such as test-driven development (TDD) and refactoring.